High Efficiency AI Training System with Supermicro and Habana Gaudi2 Processor

Enables up to 40% better price/performance for deep learning training than traditional AI solutions, for Advanced Training and Inference Performance
With the increased demand for greater training performance, throughput, and capacity, the industry needs AI training servers that offer increased efficiency, flexibility to enable customization and ease of implementation, and scaling of training systems.
Supermicro has partnered with Habana Labs to address these growing requirements. The Habana® Gaudi® AI processor is designed to maximize training throughput and efficiency while providing developers with optimized software and tools that scale to many workloads and systems.
GAUDI2 PROCESSOR FOR DEEP LEARNING TRAINING AND INFERENCE WORKLOADS.
The Gaudi2 processor significantly increases training and inference performance, building on the high-efficiency, first-generation Gaudi architecture that delivers up to 40% better price performance in the AWS cloud with Amazon EC2 DL1 instances and on-premises with the Supermicro Gaudi®2 AI Training Server.
Gaudi2 delivers training and inference performance on a whole new level with a leap from the first-gen Gaudi 16nm process technology to Gaudi2’s 7nm. It increases the number of AI-customized Tensor Processor Cores–from 8 to 24, adds support for FP8 and integrates a media processing engine for processing compressed media for offloading the host subsystem. Gaudi2’s in-package memory has tripled to 96 GB of HBM2e at 2.45 Terabytes-per-second bandwidth
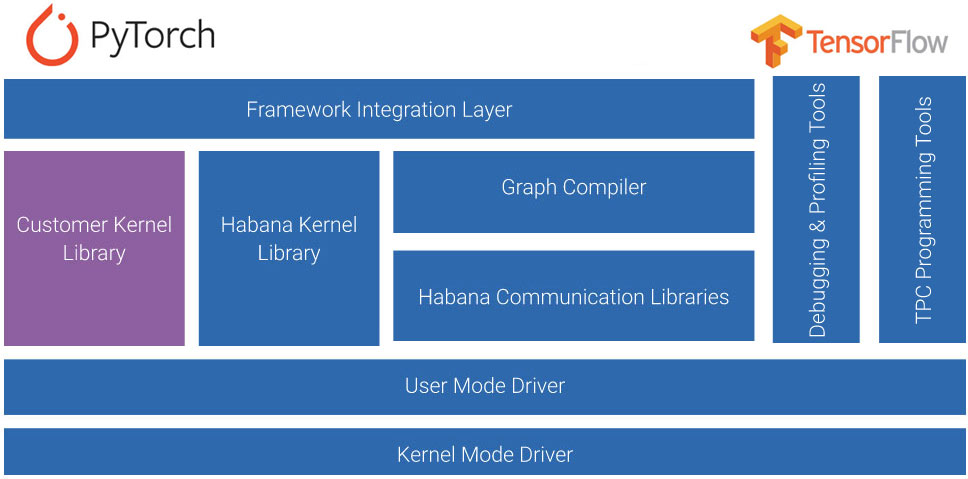
Supermicro AI Training and Inference systems
based on Habana processors are supported by Habana SynapseAI® Software Suite, offering:
• Integration of TensorFlow and PyTorch frameworks
• Popular models for computer vision and natural language processing applications
• Habana Kernel Library and enablement of Custom Kernel Development
Supermicro offers server options for both Habana Gaudi and Gaudi2 Training Server

Supermicro Gaudi®2 AI Training Server
For Advanced Training and Inference Performance
With a leap in deep learning training and inference performance while preserving cost-efficiency. Supermicro Gaudi®2 AI Training Server SYS-820GH-TNR2.
- Featuring eight Habana® Gaudi®2 AI Training Processors
- Dual 3rd Gen Intel® Xeon® Scalable processors
- Expanded networking capacity with 24x 100 Gb RoCE ports integrated onto every Gaudi2
- 700 GB/second scale within the server and 2.4TB/second scale out
- Ease of system build or migration with Habana® SynapseAI® Software Stack

Supermicro Gaudi AI Training Server
For cost-efficient training and Inference
Designed to deliver AI training efficiency, usability and scalability: Supermicro X12 Gaudi Training Server: SYS 420 GH-TNGR.
- Featuring eight Habana Gaudi HL-205 processors Four hot swappable NVMe/SATA hybrid hard drives
- Dual 3rd Gen Intel® Xeon® Scalable processors
- Each Gaudi processor contains ten 100 Gb RDMA over Converged Ethernet (RoCE) ports
- Dual-socket 3rd Gen Intel ® Xeon® Scalable Processors
- Two PCIe Gen 4 switches
- Scale out with 24x 100 Gb RoCE ports (six QSFP-DDs)
- 32 DIMMs; up to 8TB of DDR4-3200MHz