AS-8125GS-TNHR
DP AMD 8U Server with NVIDIA HGX H100/H200 8-GPU


- High density 8U system for NVIDIA® HGX™ H100/H200 8-GPU
Highest GPU communication using NVIDIA® NVLINK™ + NVIDIA® NVSwitch™
8 NIC for GPU direct RDMA (1:1 GPU Ratio) - 24 DIMM slots DDR5; up to 6TB 4800MT/s ECC LRDIMM/RDIMM
- Up to 8 PCIe 5.0 x16 LP + 4 PCIe 5.0 x16 FHFL slots
- Flexible networking options
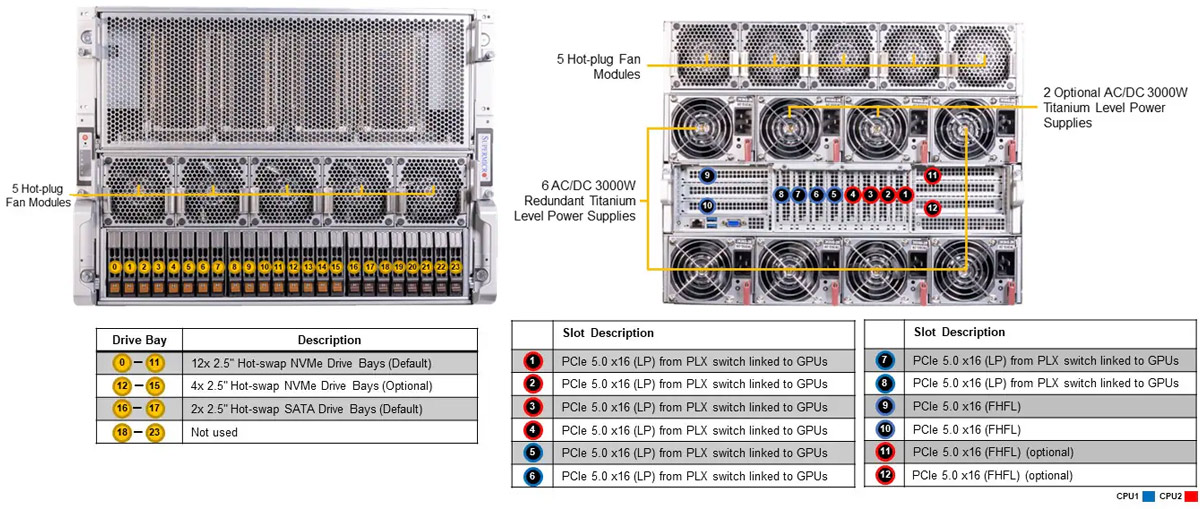
- 12 Hot-swap 2.5" NVMe drive bays + 2 hot-swap 2.5" SATA drive bays
+ 4 hot-swap 2.5" NVMe drive bays (optional)
1 M.2 NVMe for boot drive only - 10 heavy duty fans with optimal fan speed control
- 6x 3000W redundant Titanium level power supplies
Key Applications
- High Performance Computing
- AI/Deep Learning Training
- Industrial Automation, Retail
- Climate &Weather Modeling


| Product SKUs | A+ Server AS -8125GS-TNHR |
| Motherboard | Super H13DSG-O-CPU-D |
| Processor | |
| CPU | Dual Socket SP5 AMD EPYC™ 9004 Series Processors |
| Core Count | Up to 128C/256T |
| Note | Supports up to 400W TDP CPUs (Air Cooled) |
| GPU | |
| Max GPU Count | 8 onboard GPUs |
| Supported GPU | NVIDIA SXM: HGX H100 8-GPU (80GB), HGX H200 8-GPU (141GB), HGX H200 8-GPU (141GB) |
| CPU-GPU Interconnect | PCIe 5.0 x16 CPU-to-GPU Interconnect |
| GPU-GPU Interconnect | NVIDIA® NVLink® with NVSwitch™ |
| System Memory | |
| Memory | Slot Count: 24 DIMM slots Max Memory (1DPC): Up to 6TB 4800MT/s ECC DDR5 RDIMM |
| Memory Voltage | 1.1V |
| On-Board Devices | |
| Chipset | AMD SP5 |
| Input / Output | |
| Video | 1 VGA port |
| System BIOS | |
| BIOS Type | AMI 32MB SPI Flash EEPROM |
| Management | |
| Software | SuperCloud Composer® Supermicro Server Manager (SSM) Supermicro Update Manager (SUM) Supermicro SuperDoctor® 5 (SD5) Super Diagnostics Offline (SDO) Supermicro Thin-Agent Service (TAS) SuperServer Automation Assistant (SAA) New! |
| Power configurations | Power-on mode for AC power recovery ACPI Power Management |
| Security | |
| Hardware | Trusted Platform Module (TPM) 2.0 Silicon Root of Trust (RoT) – NIST 800-193 Compliant |
| Features | Cryptographically Signed Firmware Secure Boot Secure Firmware Updates Automatic Firmware Recovery Supply Chain Security: Remote Attestation Runtime BMC Protections System Lockdown |
| PC Health Monitoring | |
| CPU | Monitors for CPU Cores, Chipset Voltages, Memory 7 +1 Phase-switching voltage regulator |
| FAN | Fans with tachometer monitoring Status monitor for speed control |
| Temperature | Monitoring for CPU and chassis environment Thermal Control for fan connectors |
| Chassis | |
| Form Factor | 8U Rackmount |
| Model | CSE-GP801TS |
| Dimensions and Weight | |
| Height | 14" (355.6 mm) |
| Width | 17.2" (437 mm) |
| Depth | 33.2" (843.28 mm) |
| Package | 29.5" (H) x 27.5" (W) x 51.2" (D) |
| Weight | Gross Weight: 225 lbs (102.1 kg) Net Weight: 166 lbs (75.3 kg) |
| Available Color | Black front & silver body |
| Front Panel | |
| LED | Hard drive activity LED Network activity LEDs Power status LED System Overheat & Power Fail LED |
| Buttons | Power On/Off button System Reset button |
| Expansion Slots | |
| PCI-Express (PCIe) Configuration | Default 8 PCIe 5.0 x16 LP slots 2 PCIe 5.0 x16 FHFL slots Option A 8 PCIe 5.0 x16 LP slots 4 PCIe 5.0 x16 FHFL slots |
| Drive Bays / Storage | |
| Drive Bays Configuration | Default: Total 18 bays 2 front hot-swap 2.5" SATA drive bays 4 front hot-swap 2.5" NVMe* drive bays 12 front hot-swap 2.5" NVMe drive bays (*NVMe support may require additional storage controller and/or cables) |
| M.2 | 1 M.2 NVMe slot (M-key) |
| System Cooling | |
| Fans | 10 heavy duty fans with optimal fan speed control |
| Power Supply | |
| 6x 3000W | 6x 3000W Redundant Titanium Level (96%) power supplies |
| Operating Environment | |
| Environmental Spec. | Operating Temperature: 10°C to 35°C (50°F to 95°F) Non-operating Temperature: -40°C to 60°C (-40°F to 140°F) Operating Relative Humidity: 8% to 90% (non-condensing) Non-operating Relative Humidity: 5% to 95% (non-condensing) |
Supermicro NVIDIA HGX H100/H200
8-GPU Servers
Large-Scale AI applications demand greater computing power, faster memory bandwidth, and higher memory capacity to handle today's AI models, reaching up to trillions of parameters. Supermicro NVIDIA HGX 8-GPU Systems are carefully optimized for cooling and power delivery to sustain maximum performance of the 8 interconnected H100/H200 GPUs.
Supermicro NVIDIA HGX Systems are designed to be the scalable building block for AI clusters: each system features 8x 400G NVIDIA BlueField®-3 or ConnectX-7 NICs for a 1:1 GPU-to-NIC ratio with support for NVIDIA Spectrum-X Ethernet or NVIDIA Quantum-2 InfiniBand.
The full turn-key data center solution accelerates time-to-delivery for mission-critical enterprise use cases, and eliminates the complexity of building a large cluster, which previously was achievable only through the intensive design tuning and time-consuming optimization of supercomputing.
Proven Design Datasheet
With 32 NVIDIA HGX H100/H200 8-GPU, 8U Air-cooled Systems (256 GPUs) in 9 Racks
Key Features
- Proven industry leading architecture for large scale AI infrastructure deployments
- 256 NVIDIA H100/H200 GPUs in one scalable unit
- 20TB of HBM3 with H100 or 36TB of HBM3e with H200 in one scalable unit
- 1:1 networking to each GPU to enable NVIDIA GPUDirect RDMA and Storage for training large language model with up to trillions of parameters
- Customizable AI data pipeline storage fabric with industry leading parallel file system options
- NVIDIA AI Enterprise Software Ready
 Compute Node
Compute Node

HGX H100 Systems
Multi-Architecture Flexibility with Future-Proof Open-Standards-Based Design
Benefits & Advantages
- High performance GPU interconnect up to 900GB/s - 7x better performance than PCIe
- Superior thermal design supports maximum power/performance CPUs and GPUs
- Dedicated networking and storage per GPU with up to double the NVIDIA GPUDirect throughput of the previous generation
- Modular architecture for storage and I/O configuration flexibility
Key Features
- 8 next-generation H100 SXM GPUs with NVLink, NVSwitch interconnect
- Supports PCIe 5.0, DDR5 and Compute Express Link (CXL) 1.1+
- Innovative modular architecture designed for flexibility and futureproofing in 8U
- Optimized thermal capacity and airflow to support CPUs up to 350W and GPUs up to 700W with air cooling and optional liquid cooling
- PCIe 5.0 x16 1:1 networking slots for GPUs up to 400Gbps each supporting GPUDirect Storage and RDMA and up to 16 U.2 NVMe drive bays

Plug-and-Play for Rapid Generative AI Deployment
The SuperCluster design with 8U air-cooled (shown) or optional 4U liquid-cooled HGX systems comes with 400Gb/s of networking fabrics and non-blocking architecture. These are interconnected into four 8U (or eight 4U) nodes per rack and further into a 32-node cluster that operates as a scalable unit “SU” of compute—providing a foundational building block for generative AI infrastructure.
Whether fitting an enormous foundation model trained on a dataset with trillions of tokens from scratch or building cloud-scale LLM inference infrastructure, the SuperCluster leaf-spine network topology allows it to scale from 32 nodes to thousands of nodes seamlessly. Supermicro’s proven testing processes thoroughly validate the operational effectiveness and efficiency of compute infrastructure before shipping. Customers receive plug-and-play scalable units for rapid deployment.
32-Node Scalable Unit Rack Scale Design Close-up
SYS-821GE-TNHR / AS-8125GS-TNHR
| Overview | 8U Air-cooled System with NVIDIA HGX H100/H200 |
|---|---|
| CPU | Dual 5th/4th Gen Intel® Xeon® or AMD EPYC 9004 Series Processors |
| Memory | 2TB DDR5 (recommended) |
| GPU | NVIDIA HGX H100/H200 8-GPU (80GB HBM3 or 141GB HBM3E per GPU 900GB/S NVLink GPU-GPU Interconnect with NVLink |
| Networking | 8x NVDIA ConnectX®-7 Single-port 400Gbps/NDR OSFP NICs 2x NVDIA ConnectX®-7 Dual-port 200Gbps/NDR200 OSFP112 NICs |
| Storage | 30.4TB NVMe (4x 7.6TB U.3) 3.8TB NVMe (2x 1.9TB U.3, Boot) [Optional M.2 available] |
| Power Supply | 6x 3000W Redundant Titanium Level power supplies |
