Supermicro Generative AI SuperCluster for Large Language Models

In the era of AI, a unit of compute is no longer measured by just the number of servers. Interconnected GPUs, CPUs, memory, storage, and these resources across multiple nodes in racks construct today's artificial Intelligence. The infrastructure requires high-speed and low-latency network fabrics, and carefully designed cooling technologies and power delivery to sustain optimal performance and efficiency for each data center environment.
Supermicro’s SuperCluster solution provides foundational building blocks for rapidly evolving Generative AI and Large Language Models (LLMs).



Generative AI SuperCluster
The full turn-key data center solution accelerates time-to-delivery for mission-critical enterprise use cases, and eliminates the complexity of building a large cluster, which previously was achievable only through the intensive design tuning and time-consuming optimization of super computing.
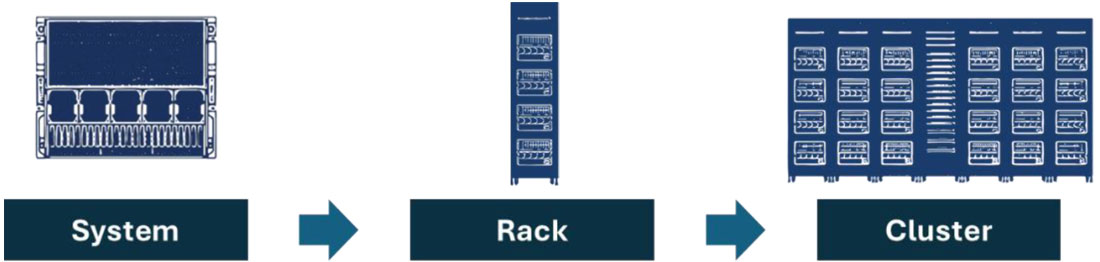
To understand how to scale effectively to the cluster level, Supermicro will profile the GPU systems that compose Supermicro’s SuperCluster solution before building up to the rack and cluster level.
Highest Density Datasheet
With 32 NVIDIA HGX H100/H200 8-GPU, 4U Liquid-cooled Systems (256 GPUs) in 5 Racks
Key Features
- Doubling compute density through Supermicro’s custom liquid-cooling solution with up to 40% reduction in electricity cost for data center
- 256 NVIDIA H100/H200 GPUs in one scalable unit
- 20TB of HBM3 with H100 or 36TB of HBM3e with H200 in one scalable unit
- 1:1 networking to each GPU to enable NVIDIA GPUDirect RDMA and Storage for training large language model with up to trillions of parameters
- Customizable AI data pipeline storage fabric with industry leading parallel file system options
- NVIDIA AI Enterprise Software Ready
 Compute Node
Compute Node

Proven Design Datasheet
With 32 NVIDIA HGX H100/H200 8-GPU, 8U Air-cooled Systems (256 GPUs) in 9 Racks
Key Features
- Proven industry leading architecture for large scale AI infrastructure deployments
- 256 NVIDIA H100/H200 GPUs in one scalable unit
- 20TB of HBM3 with H100 or 36TB of HBM3e with H200 in one scalable unit
- 1:1 networking to each GPU to enable NVIDIA GPUDirect RDMA and Storage for training large language model with up to trillions of parameters
- Customizable AI data pipeline storage fabric with industry leading parallel file system options
- NVIDIA AI Enterprise Software Ready
 Compute Node
Compute Node

Cloud-Scale Inference Datasheet
With 256 NVIDIA GH200 Grace Hopper Superchips, 1U MGX Systems in 9 Racks
Key Features
- Unified GPU and CPU memory for cloud-scale high volume, low-latency, and high batch size inference
- 1U Air-cooled NVIDIA MGX Systems in 9 Racks, 256 NVIDIA GH200 Grace Hopper Superchips in one scalable unit
- Up to 144GB of HBM3e + 480GB of LPDDR5X, enough capacity to fit a 70B+ parameter model in one node
- 400Gb/s InfiniBand or Ethernet non-blocking networking connected to spine-leaf network fabric
- Customizable AI data pipeline storage fabric with industry leading parallel file system options NVIDIA AI Enterprise software ready
 Compute Node
Compute Node

Enterprise 3D + AI Datasheet
With 32 4U PCIe GPU Air-Cooled Systems (up to 256 NVIDIA L40S GPUs) in 5 Racks
Key Features
- Maximize multi-workload performance for enterprise AI-enabled workflows.
- Optimized for NVIDIA Omniverse with OpenUSD.
- 256 NVIDIA L40S GPUs in one scalable unit
- 12TB of GPU memory and 32TB of system memory in one scalable unit
- Scale-out with 400Gb/s NVIDIA Spectrum™-X Ethernet
- Customizable data storage fabric with industry leading parallel file system options
- Certified for NVIDIA Omniverse Enterprise with included Enterprise Support Services
 Compute Node
Compute Node

Rack-Scale Liquid Cooling Solutions: Superior Cooling, Density, and Sustainability
Supermicro liquid cooling solution can reduce OPEX by up to 40%, and allow data centers to run more efficiently with lower PUE. Supermicro has proven liquid cooling deployments at scale and enables data centers operators to deploy the latest and most performance CPUs and GPUs.
 Up to 40% REDUCTION
Up to 40% REDUCTION in Electricity Costs for Entire Data Center
 Up to 55% REDUCTION
Up to 55% REDUCTION in Data Center Server Noise
 Up to 89% REDUCTION
Up to 89% REDUCTION in Electricity Costs of Cooling Infrastructure in Server